



python模拟登陆、POST/GET请求方式
(福利推荐:你还在原价购买阿里云服务器?现在阿里云0.8折限时抢购活动来啦!4核8G企业云服务器仅2998元/3年,立即抢购>>>:9i0i.cn/aliyun)
python模拟登陆、POST/GET请求
通常我们在访问网页时,都会通过某个输入框输入数据,网页就会发出POST、GET或者其他形式向服务器发起请求,成功后并返回数据到前台展示。以下针对python的requests库做简单介绍。
前提先安装python以及requests库
安装requests:
pip install requests
请求测试url = http://www.test.com
一、GET请求
1、无请求参数:直接访问某url链接即可获取数据
result = requests.get(url=url) print(result.status_code) # 请求状态 print(result.url)# 请求url print(result.text) # 请求结果
2、有请求参数:键值对形式表示参数
result = requests.get(url=url, params={'keyword1':'val1','keyword2':'val2'})
#或者可以直接先拼接url
#new_url = url + '?keyword1=' + val1 + '&keyword1=' +val2
#result = requests.get(url=new_url)
print(result.status_code) # 请求状态
print(result.url)# 请求url
print(result.text) # 请求结果
3、有请求头部参数:键值对形式表示参数
result = requests.get(url=url, params={'keyword1':'val1','keyword2':'val2'})
#或者可以直接先拼接url
#new_url = url + '?keyword1=' + val1 + '&keyword1=' +val2
#result = requests.get(url=new_url)
print(result.status_code) # 请求状态
print(result.url)# 请求url
print(result.text) # 请求结果
二、POST请求
1、请求的结果集是application/x-www-form-urlencoded
result = requests.post(url=url,data={'keyword1':'val1','keyword2':'val2'},headers={'Content-Type':'application/x-www-form-urlencoded'})
print(result.status_code) # 请求状态
print(result.url)# 请求url
print(result.text) # 请求结果
2、请求的结果集是multipart/form-data
result = requests.post(url=url,data={'keyword1':'val1','keyword2':'val2'},headers={'Content-Type':'multipart/form-data'})
print(result.status_code) # 请求状态
print(result.url)# 请求url
print(result.text) # 请求结果
3、请求的结果集是application/json
import json
data = {'keyword1':'val1','keyword2':'val2'}
json_data = json.dumps(data)
result = requests.post(url=url,data=json_data,headers={'Content-Type':'application/json'})
print(result.status_code) # 请求状态
print(result.url)# 请求url
print(result.text) # 请求结果
如下图:

下来来说一下之前自己遇到的坑,请求方式为POST,且为Request Payload形式的请求。
一开始自以为跟form-data一样,只传一个url跟data,且data没有格式化成JSON,导致请求回来的状态为415:服务器无法处理请求附带的媒体格式,经查阅后来改个格式以及请求头就顺利返回数据。
完整demo如下:
import json
import requests
import datetime
import re, urllib.request, lxml.html, http.cookiejar
url = 'http://test.com/products'
# payloadData数据
payload_data = {'keyword1': "val1", 'keyword2': "val2"}
# 请求头设置
payload_header = {
'Host': 'test.com',
'Content-Type': 'application/json; charset=UTF-8',
}
# 下载超时
timeout = 30
# 代理IP
# proxy_list = {"HTTP":'http://210.22.5.117"3128',"HTTP":'http://163.172.189.32:8811',"HTTP":'http://180.153.144.138:8800'}
json_data = json.dumps(payload_data)
# allow_redirects 是否重定向
# result = requests.post(url=url, data=json_data, headers=payloadHeader, timeout=timeout, proxies=proxy_list, allow_redirects=True)
result = requests.post(url, data=json_data, headers=payload_header, timeout=timeout, allow_redirects=True)
# 下面这种直接填充json参数的方式也OK
# result = requests.post(url, json=json_data, headers=payload_header)
print("请求耗时:{0}, 状态码:{1}, 结果:{2}".format(datetime.datetime.now(),res.status_code,res.text))
三、需要模拟登陆后再发送Post请求
有时候就想模拟页面上的某些细微的操作,例如登录后需要在前端利用ajax请求修改数据。
如果只是极个别数量修改的话,那还是前端直接操作快一点。
如果是大批量的修改那还是得借住程序遍历修改即可。
登录页面:
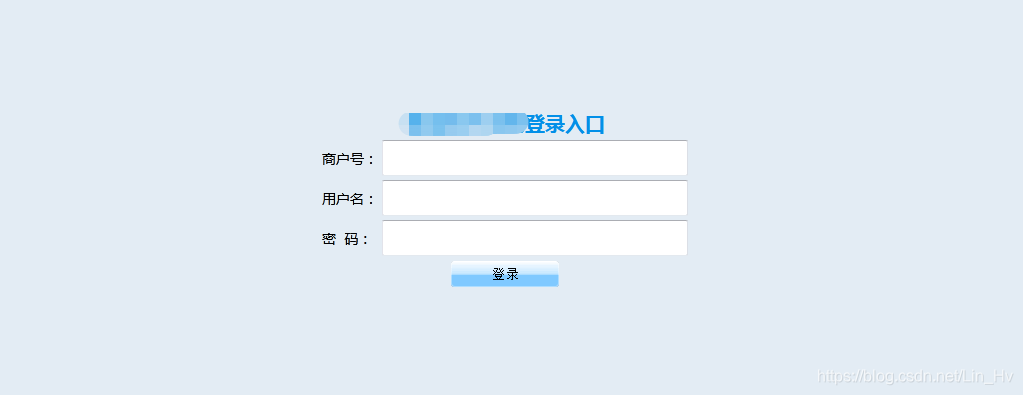
先打开F12进入开发者模式,然后随便在上面的表单输入框数据,点击登录,虽然是错误的登录数据,我们只是为了查看登录请求提交的数据格式,如下图:

其中的某些不是我们输入的隐藏值,我们需要到页面源码中的表单获取,右键查看页面源码,把那些非自己输入的 “__VIEWSTATE",”__VIEWSTATEGENERATOR","__EVENTVALIDATION" 的值到原页面中查找,例如:
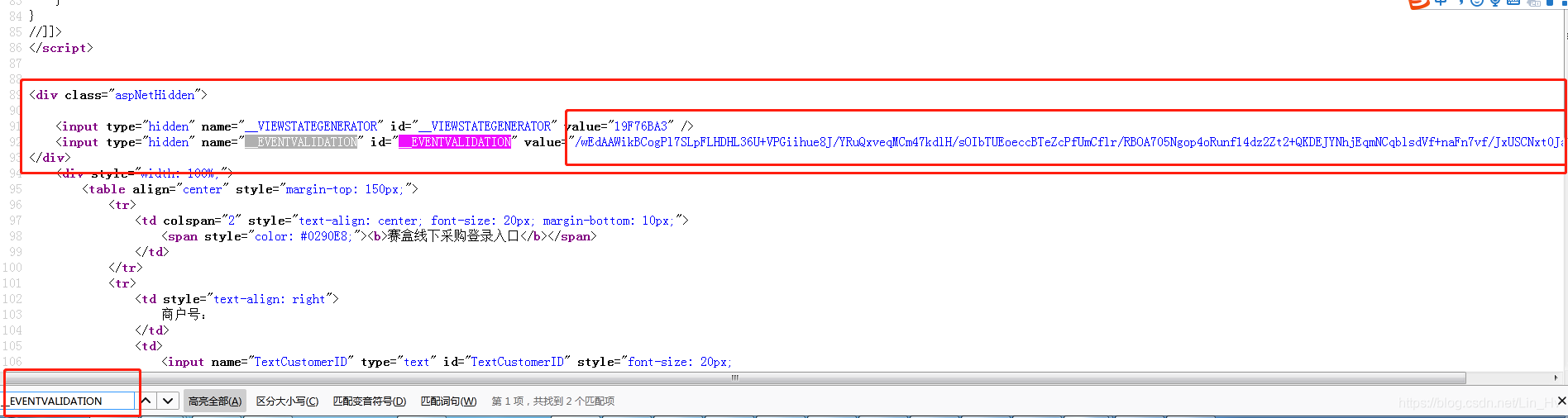
也就是说我们得事先先访问该页面页面源码并解析获取以上属性值:
import requests, string
import re, urllib.request, lxml.html, http.cookiejar
login_url = "http://test.com/Login.aspx"
response = urllib.request.urlopen(login_url)
f = response.read()
doc = lxml.html.document_fromstring(f)
VIEWSTATE = doc.xpath("//input[@id='__VIEWSTATE']/@value")
VIEWSTATEGENERATOR = doc.xpath("//input[@id='__VIEWSTATEGENERATOR']/@value")
EVENTVALIDATION = doc.xpath("//input[@id='__EVENTVALIDATION']/@value")
获取到这些之后,得把这些值放回到Form-Data(表单数据中):
from urllib.parse import quote
login_data = urllib.parse.urlencode({
'__EVENTTARGET' : '',
'__EVENTARGUMENT' : '',
'__VIEWSTATE' : VIEWSTATE[0],
'__VIEWSTATEGENERATOR' : VIEWSTATEGENERATOR[0],
'__EVENTVALIDATION' : EVENTVALIDATION[0],
'TextCustomerID' : "真实商户号",
'TextAdminName' : '真实用户名',
'TextPassword' : '真实密码',
'btnLogin.x' : 40,
'btnLogin.y' : 10
}).encode('utf-8')
登录参数的编码很重要,如果没有进行utf-8编码会报以下错误:
Traceback (most recent call last):
File "c:\users\user\appdata\local\programs\python\python38\lib\http\client.py", line 965, in send
self.sock.sendall(data)
File "c:\users\user\appdata\local\programs\python\python38\lib\ssl.py", line 1201, in sendall
with memoryview(data) as view, view.cast("B") as byte_view:
TypeError: memoryview: a bytes-like object is required, not 'str'
表单数据有了,接下来就是把请求头也要获取出来:

header = {
'Host': 'www.test.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate',
'Content-Type': 'application/x-www-form-urlencoded',
'Origin': 'http://www.test.com',
'Connection': 'keep-alive',
'Referer': 'http://www.test.com/Login.aspx',
'Upgrade-Insecure-Requests': 1
}
模拟登陆并保存cookie:
#模拟登录请求 login_request = urllib.request.Request(login_url, login_data, Headers) #创建cookie,利用cookie实现持久化登录 cj = http.cookiejar.CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) login_result = opener.open(login_request)
最后模拟登陆后,如果是要采集某页面数据的话也可以通过urllib.request.urlopen访问页面链接读取页面源码进行数据采集。
如果有批量数据需要进行Post/Get处理,那么就可以把待处理的数据获取好,然后遍历发起Post或Get请求即可:
import time, random
var datas = {.....}
for data in datas:
response = requests.get(url, headers = headers, data=json_data, cookies = cj)
# 或
response = requests.post(url, headers = headers, data=json_data, cookies = cj)
time.sleep(random.randint(3, 5))
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持程序员之家。
相关文章
 JSON 是一个很好的选择。如果你对 Python 有所了解,就更加事半功倍了。下面就来介绍一下如何使用 Python 处理 JSON 数据。感兴趣的朋友跟随小编一起看看吧2019-07-07
JSON 是一个很好的选择。如果你对 Python 有所了解,就更加事半功倍了。下面就来介绍一下如何使用 Python 处理 JSON 数据。感兴趣的朋友跟随小编一起看看吧2019-07-07
windows系统多个python中更改默认python版本
这篇文章主要给大家介绍了关于windows系统多个python中更改默认python版本的相关资料,在Python开发中,不同的项目往往需要使用不同的Python版本,需要的朋友可以参考下2023-09-09 使用消息队列在数据的通信中拥有很多优点,SnakeMQ是一个开源的用Python实现的跨平台MQ库,well,Python的消息队列包SnakeMQ使用初探,here we go:2016-06-06
使用消息队列在数据的通信中拥有很多优点,SnakeMQ是一个开源的用Python实现的跨平台MQ库,well,Python的消息队列包SnakeMQ使用初探,here we go:2016-06-06 这篇文章主要为大家详细介绍了python+mysql实现个人论文管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-10-10
这篇文章主要为大家详细介绍了python+mysql实现个人论文管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-10-10 这篇文章主要介绍了如何处理Python3.4 使用pymssql 乱码问题的相关资料,涉及到python pymssql相关知识,对此感兴趣的朋友一起学习吧2016-01-01
这篇文章主要介绍了如何处理Python3.4 使用pymssql 乱码问题的相关资料,涉及到python pymssql相关知识,对此感兴趣的朋友一起学习吧2016-01-01 Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言,下面这篇文章主要给大家介绍了关于如何在python中创建表格的两种方法,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-01-01
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言,下面这篇文章主要给大家介绍了关于如何在python中创建表格的两种方法,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-01-01 这篇文章主要介绍了Django admin高级用法,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了Django admin高级用法,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2019-11-11 本篇文章主要介绍了Python实现XML文件解析的示例代码,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-02-02
本篇文章主要介绍了Python实现XML文件解析的示例代码,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-02-02 枚举类型在编程中扮演着重要的角色,它们为变量赋予了更加清晰的含义,然而,在Python中,实现自增的枚举类并非直接而简单的任务,本文将深入讨论如何通过不同的方式优雅地实现自增的枚举类,需要的朋友可以参考下2023-12-12
枚举类型在编程中扮演着重要的角色,它们为变量赋予了更加清晰的含义,然而,在Python中,实现自增的枚举类并非直接而简单的任务,本文将深入讨论如何通过不同的方式优雅地实现自增的枚举类,需要的朋友可以参考下2023-12-12 这篇文章主要为大家详细介绍了python监控nginx端口和进程状态,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-09-09
这篇文章主要为大家详细介绍了python监控nginx端口和进程状态,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-09-09


最新评论