



PyTorchЪЙгУTricks:Dropout,R-DropoutКЭMulti-Sample?DropoutЗНЪН
ЃЈИЃРћЭЦМіЃКФуЛЙдкдМлЙКТђАЂРядЦЗўЮёЦїЃПЯждкАЂРядЦ0.8елЯоЪБЧРЙКЛюЖЏРДРВЃЁ4КЫ8GЦѓвЕдЦЗўЮёЦїНі2998дЊ/3ФъЃЌСЂМДЧРЙК>>>ЃК9i0i.cn/aliyunЃЉ
1ЁЂЮЊЪВУДЪЙгУDropoutЃП
DropoutЪЧвЛжждкЩёОЭјТчбЕСЗЙ§ГЬжагУгкЗРжЙЙ§ФтКЯЕФММЪѕЁЃдкбЕСЗЙ§ГЬжаЃЌDropoutЛсЫцЛњЕиЙиБевЛВПЗжЩёОдЊЃЌетбљПЩвдЪЙФЃаЭИќМгНЁзГЃЌВЛЛсЙ§ЖШвРРЕгкШЮКЮвЛИіЬиЖЈЕФЩёОдЊЃЌДгЖјЬсИпФЃаЭЕФЗКЛЏФмСІЁЃЯТУцЪЧвЛаЉЪЙгУММЧЩЃК
ММЧЩ1ЃКдкЪфШыВуКЭвўВиВуЩЯЪЙгУDropoutЁЃетИіММЧЩЪЧЛљгкDropoutЕФСНИізїгУЃЌМДдіМгЭјТчЕФЖрбљадКЭдіМгЪ§ОнЕФЖрбљадЁЃдкЪфШыВуЩЯЪЙгУDropoutЃЌЯрЕБгкЖдЪ§ОнНјаадыЩљзЂШыЃЌПЩвдЬсИпЪ§ОнЕФТГАєадЃЌЗРжЙЭјТчЖдЪ§ОнЕФЯИНкЙ§ЖШУєИаЁЃдквўВиВуЩЯЪЙгУDropoutЃЌЯрЕБгкЖдЭјТчНјаазгВЩбљЃЌПЩвдЬсИпЭјТчЕФЗКЛЏФмСІЃЌЗРжЙЭјТчЖдЬиЖЈЕФЬиеїЙ§ЖШвРРЕЁЃдкЭјТчЕФУПвЛВуЖМЪЙгУDropoutЃЌПЩвдНјвЛВНдіЧПетСНИізїгУЃЌЕЋвВвЊзЂвтВЛвЊЙ§ЖШЪЙгУЃЌЕМжТЭјТчЕФбЕСЗВЛГфЗжЁЃ
ММЧЩ2ЃКЭјТчжаЕФDropoutТЪЮЊ0.2~0.5ЁЃетИіММЧЩЪЧЛљгкОбщЕФНЈвщЃЌвЛАуРДЫЕЃЌDropoutТЪЬЋЕЭЛсЕМжТDropoutЕФаЇЙћВЛУїЯдЃЌDropoutТЪЬЋИпЛсЕМжТЭјТчЕФбЕСЗВЛГфЗжЁЃВЛЙ§ЃЌетИіММЧЩвВВЛЪЧОјЖдЕФЃЌгааЉбаОПЗЂЯжЃЌDropoutТЪПЩвдГЌЙ§0.5ЃЌЩѕжСНгНќ1ЃЌШдШЛПЩвдШЁЕУКмКУЕФаЇЙћЁЃетПЩФмШЁОігкЭјТчЕФИДдгЖШЃЌЪ§ОнЕФЙцФЃЃЌвдМАЦфЫћЕФе§дђЛЏЗНЗЈЁЃ
ММЧЩ3ЃКдкНЯДѓЕФЭјТчЩЯЪЙгУDropoutЁЃетИіММЧЩЪЧЛљгкDropoutЕФБОжЪЃЌМДЭЈЙ§ЫцЛњЕиЩОГ§ЭјТчжаЕФвЛаЉСЌНгЃЌРДЗРжЙЭјТчЕФЙ§ФтКЯЁЃдкНЯДѓЕФЭјТчЩЯЃЌЙ§ФтКЯЕФЗчЯеИќИпЃЌвђДЫDropoutЕФзїгУИќУїЯдЁЃВЛЙ§ЃЌетВЂВЛвтЮЖзХдкНЯаЁЕФЭјТчЩЯЪЙгУDropoutОЭУЛгавтвхЃЌжЛЪЧаЇЙћПЩФмВЛШчдкНЯДѓЕФЭјТчЩЯЯджјЁЃ
ММЧЩ4ЃКЪЙгУНЯИпЕФбЇЯАТЪЃЌЪЙгУбЇЯАТЪЫЅМѕКЭЩшжУНЯДѓЕФЖЏСПжЕЁЃетИіММЧЩЪЧЛљгкDropoutЕФСэвЛИізїгУЃЌМДдіМгЭјТчЕФЮШЖЈадЁЃгЩгкDropoutЛсЫцЛњЕиИФБфЭјТчЕФНсЙЙЃЌЕМжТЭјТчЕФЪфГігаНЯДѓЕФЗНВюЃЌвђДЫашвЊЪЙгУНЯИпЕФбЇЯАТЪЃЌРДМгПьЭјТчЕФЪеСВЫйЖШЁЃЭЌЪБЃЌЪЙгУбЇЯАТЪЫЅМѕЃЌПЩвддкЭјТчНгНќзюгХНтЪБЃЌМѕаЁбЇЯАТЪЃЌБмУтЭјТчЕФе№ЕДЁЃСэЭтЃЌЪЙгУНЯДѓЕФЖЏСПжЕЃЌПЩвддіМгЭјТчЕФЙпадЃЌЕжПЙDropoutДјРДЕФШХЖЏЃЌБЃГжЭјТчЕФЗНЯђЁЃетИіММЧЩЕФОпЬхВЮЪ§ЃЌашвЊИљОнЭјТчЕФНсЙЙКЭЪ§ОнЕФЬиЕуНјааЕїНкЁЃ
ММЧЩ5ЃКЯожЦЭјТчШЈжиЕФДѓаЁЃЌЪЙгУзюДѓЗЖЪ§е§дђЛЏЁЃетИіММЧЩЪЧЛљгкDropoutЕФвЛИіОжЯоЃЌМДDropoutВЛФмЭъШЋЗРжЙЭјТчЕФЙ§ФтКЯЁЃгШЦфЪЧЪЙгУНЯИпЕФбЇЯАТЪЪБЃЌЭјТчЕФШЈжиПЩФмЛсБфЕУЗЧГЃДѓЃЌЕМжТЭјТчЕФЪфГіЙ§гкУєИаЃЌНЕЕЭЭјТчЕФЗКЛЏФмСІЁЃвђДЫЃЌашвЊЖдЭјТчЕФШЈжиНјаадМЪјЃЌЯожЦЦфДѓаЁЃЌЗРжЙЭјТчЕФЙ§ФтКЯЁЃзюДѓЗЖЪ§е§дђЛЏЪЧвЛжжГЃгУЕФЗНЗЈЃЌЫќПЩвдЯожЦЭјТчЕФШЈжиЕФЗЖЪ§ВЛГЌЙ§вЛИіИјЖЈЕФуажЕЃЌДгЖјПижЦЭјТчЕФИДдгЖШЁЃ
ЯТУцЪЧвЛИіР§згЃК
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer1 = nn.Linear(10, 20)
self.layer2 = nn.Linear(20, 20)
self.layer3 = nn.Linear(20, 4)
self.dropout = nn.Dropout(p=0.5)
def forward(self, x):
x = F.relu(self.layer1(x))
x = self.dropout(x)
x = F.relu(self.layer2(x))
x = self.dropout(x)
return self.layer3(x)2ЁЂDropoutЕФЭиеЙ1ЃКR-Dropout
КЫаФЫМЯыЃКR-DropoutЕФКЫаФЫМЯыЪЧдкбЕСЗЙ§ГЬжаЭЈЙ§е§дђЛЏЪжЖЮМѕЩйФЃаЭдкЭЌвЛЪфШыЪ§ОнЩЯСНДЮЧАЯђДЋВЅЃЈУПДЮЖМгІгУDropoutЃЉНсЙћжЎМфЕФВювьЁЃетжжЗНЗЈЧПжЦФЃаЭдкУцЖдЪфШыЪ§ОнЕФВЛЭЌ“ЪгНЧ”ЃЈМДЃЌВЛЭЌЕФDropoutбкТыЃЉЪБЃЌбЇЯАЕНИќвЛжТЕФБэЪОЁЃЭЈЙ§етжжЗНЪНЃЌR-DropoutЙФРјФЃаЭВЖЛёИќЮШНЁЕФЬиеїЃЌДгЖјЬсИпФЃаЭЕФЗКЛЏФмСІЁЃ
ЪЕЯжЗНЪНЃКЪЕЯжR-DropoutЪБЃЌЭЈГЃЛсЖдЭЌвЛХњЪ§ОнНјааСНДЮЖРСЂЕФЧАЯђДЋВЅЃЌУПДЮЧАЯђДЋВЅЖМгІгУВЛЭЌЕФDropoutФЃЪНЁЃШЛКѓЃЌЭЈЙ§БШНЯетСНДЮЧАЯђДЋВЅЕФНсЙћЃЈР§ШчЃЌЪЙгУKLЩЂЖШзїЮЊСНИіЗжВМжЎМфВювьЕФЖШСПЃЉЃЌНЋетжжВювьзїЮЊЖюЭтЕФе§дђЛЏЫ№ЪЇЬэМгЕНзмЫ№ЪЇжаЁЃ
ЯТУцЪЧвЛИіМђЕЅЕФР§згЃЌеЙЪОСЫШчКЮдквЛИіМђЕЅЕФШЋСЌНгЩёОЭјТчжаЪЕЯжR-DropoutЁЃ
ЪЙгУKLЩЂЖШзїЮЊЧАСНДЮЧАЯђДЋВЅНсЙћжЎМфВювьЕФЖШСПЃЌВЂНЋЦфЬэМгЕНдЪМЫ№ЪЇжаЁЃ
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class RDropoutNN(nn.Module):
def __init__(self):
super(RDropoutNN, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(256, 10)
def forward(self, x, with_dropout=True):
x = F.relu(self.fc1(x))
if with_dropout:
x = self.dropout(x)
x = self.fc2(x)
return x
def compute_kl_loss(p, q):
p_log_q = F.kl_div(F.log_softmax(p, dim=1), F.softmax(q, dim=1), reduction='sum')
q_log_p = F.kl_div(F.log_softmax(q, dim=1), F.softmax(p, dim=1), reduction='sum')
return (p_log_q + q_log_p) / 2
# МйЩш
model = RDropoutNN()
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# МйЩшгавЛИіЪ§ОнМгдиЦї
# for inputs, labels in data_loader:
# ФЃФтЪ§Он
inputs = torch.randn(64, 784) # МйЩшЕФЪфШы
labels = torch.randint(0, 10, (64,)) # МйЩшЕФБъЧЉ
# ЧхСуЬнЖШ
optimizer.zero_grad()
# СНДЮЧАЯђДЋВЅЃЌУПДЮЖМЪЙгУDropout
outputs1 = model(inputs, with_dropout=True)
outputs2 = model(inputs, with_dropout=True)
# МЦЫудЪМЫ№ЪЇ
loss1 = criterion(outputs1, labels)
loss2 = criterion(outputs2, labels)
original_loss = (loss1 + loss2) / 2
# МЦЫуR-Dropoutе§дђЛЏЯю
kl_loss = compute_kl_loss(outputs1, outputs2)
# зюжеЫ№ЪЇ
lambda_kl = 0.5 # R-Dropoutе§дђЛЏЯюЕФШЈжи
total_loss = original_loss + lambda_kl * kl_loss
# ЗДЯђДЋВЅКЭгХЛЏ
total_loss.backward()
optimizer.step()дкетИіР§згжаЃЌЖдЯрЭЌЕФЪфШыжДааСНДЮЧАЯђДЋВЅЃЌУПДЮЖМгІгУDropoutЁЃШЛКѓЃЌЗжБ№МЦЫуетСНИіЪфГіЖдгІЕФНЛВцьиЫ№ЪЇЃЌВЂНЋЫќУЧЕФЦНОљжЕзїЮЊдЪМЫ№ЪЇЁЃНгзХЃЌЪЙгУKLЩЂЖШМЦЫуСНДЮЪфГіжЎМфЕФВювьзїЮЊR-DropoutЕФе§дђЛЏЯюЃЌВЂНЋЦфМгЕНдЪМЫ№ЪЇжавдЕУЕНзюжеЕФЫ№ЪЇЁЃзюКѓЃЌЭЈЙ§ЗДЯђДЋВЅИќаТФЃаЭЕФШЈжиЁЃ
ЭЈЙ§в§ШыR-Dropoutе§дђЛЏЯюЃЌЙФРјФЃаЭЩњГЩИќвЛжТЕФЪфГіЃЌМДЪЙдкгІгУВЛЭЌЕФDropoutбкТыЪБвВЪЧШчДЫЁЃетгажњгкЬсИпФЃаЭЕФЗКЛЏФмСІЃЌВЂНјвЛВНМѕЩйЙ§ФтКЯЕФЗчЯеЁЃ
3ЁЂDropoutЕФЭиеЙ2ЃКMulti-Sample Dropout
КЫаФЫМЯыЃКMulti-Sample DropoutЕФКЫаФЫМЯыЪЧдкЕЅДЮЧАЯђДЋВЅЙ§ГЬжаЖдЭЌвЛЪфШыгІгУЖрДЮDropoutЃЌВњЩњЖрИіВЛЭЌЕФбкТыЃЌВЂЖдНсЙћНјааОлКЯЃЈР§ШчЃЌЭЈЙ§ШЁЦНОљЛЏЃЉЁЃетжжЗНЗЈЕФФПЕФЪЧдкУПДЮбЕСЗЕќДњжаИќГфЗжЕиРћгУDropoutЃЌвдЪЕЯжИќПьЕФЪеСВКЭИќКУЕФЗКЛЏЁЃ
ЪЕЯжЗНЪНЃКдкЪЕЯжMulti-Sample DropoutЪБЃЌЛсдкФЃаЭЕФЙиМќВужаВЂаав§ШыЖрИіDropoutВуЃЌУПИіDropoutВуЖдЪфШыЪ§ОнгІгУВЛЭЌЕФЫцЛњбкТыЁЃШЛКѓЃЌНЋетаЉDropoutВуЕФЪфГівдФГжжЗНЪНЃЈЭЈГЃЪЧЦНОљЃЉКЯВЂЃЌвдВњЩњзюжеЕФЪфГіЁЃетжжЗНЗЈдЫааФЃаЭдкУПДЮЕќДњжаПМТЧЖржж“ЖЊЦњФЃЪН”ЃЌДгЖјдіМгСЫбЕСЗЕФТГАєадЁЃ

вдЯТЪЧвЛИіЪЙгУMulti-Sample DropoutЕФР§згЃК
class MultiSampleDropout(nn.Module):
def __init__(self, dropout_rate, num_samples):
super(MultiSampleDropout, self).__init__()
self.dropout_rate = dropout_rate
self.num_samples = num_samples
def forward(self, x):
outputs = []
for _ in range(self.num_samples):
output = F.dropout(x, self.dropout_rate, training=self.training)
outputs.append(output)
return torch.mean(torch.stack(outputs), dim=0)дкУПДЮЧАЯђДЋВЅЙ§ГЬжаЖдЪфШыНјааЖрДЮВЩбљЃЌШЛКѓНЋетаЉВЩбљЕФНсЙћКЯВЂЃЌДгЖјЕУЕНзюжеЕФЪфГіЁЃ
вдЩЯСНжжЭиеЙЕФЧјБ№ЃК
- ФПБъВЛЭЌЃКR-DropoutВржигкЭЈЙ§МѕЩйЭЌвЛЪфШыдкВЛЭЌDropoutФЃЪНЯТЕФЪфГіВювьРДЬсИпЪфГіЕФвЛжТадЃЌЖјMulti-Sample DropoutВржигкдкЕЅДЮЕќДњжаЬНЫїЖржжDropoutФЃЪНЃЌвдМгЫйбЕСЗВЂЬсИпЗКЛЏЁЃ
- ЪЕЯжЛњжЦВЛЭЌЃКR-DropoutЭЈЙ§ЖдЭЌвЛХњЪ§ОнНјааСНДЮЧАЯђДЋВЅВЂМЦЫуе§дђЛЏЫ№ЪЇРДЪЕЯжЃЌЖјMulti-Sample DropoutдкЕЅДЪЧАЯђДЋВЅжагІгУЖрИіDropoutбкТыВЂОлКЯНсЙћЁЃ
- е§дђЛЏЗНЗЈВЛЭЌЃКR-Dropoutв§ШыСЫвЛИіЛљгкСНДЮЧАЯђДЋВЅНсЙћВювьЕФЖюЭте§дђЛЏЯюЃЌMulti-Sample DropoutдђЭЈЙ§ОлКЯЖрИіDropoutбљБОЕФНсЙћРДЬсИпЗКЛЏФмСІЃЌВЛашвЊЖюЭтЕФе§дђЛЏЯюЁЃ
4ЁЂDropoutЕФЭиеЙ3ЃКDropConnect
DropoutЭЈЙ§ЫцЛњНЋЩёОдЊЕФМЄЛюЪфГіжУЮЊСуРДЙЄзїЃЌЖјDropConnectдђЪЧЫцЛњНЋЭјТчЕФШЈжижУЮЊСуЁЃетвтЮЖзХдкDropConnectжаЃЌЭјТчЕФСЌНгЃЈМДШЈжиЃЉВПЗжБЛЫцЛњ“ЖЊЦњ”ЃЌЖјВЛЪЧЪфГіЁЃетжжЗНЗЈПЩвдЪгЮЊDropoutЕФвЛжжЗКЛЏаЮЪНЃЌВЂЧвРэТлЩЯПЩвдЬсЙЉИќЧПЕФе§дђЛЏаЇЙћЃЌвђЮЊЫќжБНгВйзїФЃаЭЕФШЈжиЁЃ
DropConnectЕФЙЄзїдРэЃКдкУПДЮбЕСЗЕќДњжаЃЌDropConnectЫцЛњбЁдёвЛВПЗжШЈжиЃЌВЂНЋетаЉШЈжиднЪБЩшжУЮЊ0ЁЃетИіЙ§ГЬМѕЩйСЫФЃаЭЕФШнСПЃЌЦШЪЙЭјТчдкШБЩйвЛВПЗжСЌНгЕФЧщПіЯТбЇЯАЃЌДгЖјгажњгкЗРжЙЙ§ФтКЯЁЃгыDropoutВЛЭЌЃЌDropoutConnectВЛЪЧЖЊЦњЩёОдЊЕФЪфГіЃЌЖјЪЧжБНгдкЭјТчЕФШЈжиЩЯЪЉМгдМЪјЁЃ
DropConnectЕФЪЕЯжЃКдкPyTorchжаЪЕЯжDropConnectЯрЖдМђЕЅЃЌЕЋашвЊздЖЈвхЭјТчВуЃЌвђЮЊPyTorchЕФБъзМВуВЛжБНгжЇГжетжжВйзїЁЃЯТУцЪЧвЛИіМђЕЅЕФЪОР§ЃЌеЙЪОСЫШчКЮЪЕЯжвЛИіОпгаDropConnectЙІФмЕФШЋСЌНгВуЃК
import torch
import torch.nn as nn
import torch.nn.functional as F
class DropConnect(nn.Module):
def __init__(self, input_dim, output_dim, drop_prob=0.5):
super(DropConnect, self).__init__()
self.drop_prob = drop_prob
self.weight = nn.Parameter(torch.randn(input_dim, output_dim))
self.bias = nn.Parameter(torch.randn(output_dim))
def forward(self, x):
if self.training:
# ЩњГЩгыШЈжиЯрЭЌаЮзДЕФбкТы
mask = torch.rand(self.weight.size()) > self.drop_prob
# гІгУDropConnectЃКгУбкТыГЫвдШЈжи
drop_weight = self.weight * mask.float().to(self.weight.device)
else:
# дкВтЪдЪБВЛгІгУDropConnectЃЌЕЋвЊЕїећШЈживдЗДгГЖЊЦњТЪ
drop_weight = self.weight * (1 - self.drop_prob)
return F.linear(x, drop_weight, self.bias)
# ЪЙгУDropConnectВуЕФЪОР§ЭјТч
class ExampleNet(nn.Module):
def __init__(self):
super(ExampleNet, self).__init__()
self.dropconnect_layer = DropConnect(20, 10, drop_prob=0.5)
self.fc2 = nn.Linear(10, 2)
def forward(self, x):
x = F.relu(self.dropconnect_layer(x))
x = self.fc2(x)
return x
# ЪОР§ЪЙгУ
model = ExampleNet()
input = torch.randn(5, 20) # МйЩшЕФЪфШы
output = model(input)
print(output)дкетИіР§згжаЃЌDropConnectРрЖЈвхСЫвЛИіздЖЈвхЕФШЋСЌНгВуЃЌЦфжаАќКЌСЫDropConnectЙІФмЁЃдкУПДЮЧАЯђДЋВЅЪБЃЌШчЙћФЃаЭДІгкбЕСЗФЃЪНЃЌЫќЛсЫцЛњЩњГЩвЛИігыШЈжиЯрЭЌаЮзДЕФбкТыЃЌВЂгУетИібкТыГЫвдШЈжиЃЌДгЖјЪЕЯжDropConnectаЇЙћЁЃдкЦРЙРФЃЪНЯТЃЌЮЊСЫБЃГжЪфГіЕФЦкЭћжЕВЛБфЃЌШЈжиЛсБЛЕїећЃЌвдЗДгГдкбЕСЗЪБЕФЦНОљЖЊЦњТЪЁЃ
етжжздЖЈвхВуПЩвдБЛЧЖШыЕНИќИДдгЕФЭјТчНсЙЙжаЃЌвдЬсЙЉDropConnectе§дђЛЏЕФаЇЙћЃЌДгЖјАяжњМѕЩйЙ§ФтКЯВЂЬсИпФЃаЭЕФЗКЛЏФмСІЁЃ
5ЁЂDropoutЕФЭиеЙ4ЃКStandout
StandoutЪЧвЛжжздЪЪгІЕФе§дђЛЏЗНЗЈЃЌРрЫЦгкDropoutКЭDropConnectЃЌЕЋЫќЭЈЙ§вРРЕгкЭјТчЕФМЄЛюРДЖЏЬЌЕїећУПИіЩёОдЊБЛЖЊЦњЕФИХТЪЁЃ
етжжЗНЗЈЕФКЫаФЫМЯыЪЧРћгУЩёОЭјТчФкВПЕФзДЬЌРДОіЖЈФФаЉЩёОдЊИќПЩФмБЛБЃСєЃЌДгЖјЪЙе§дђЛЏЙ§ГЬИќМгвРРЕгкФЃаЭЕБЧАЕФааЮЊЁЃ
етжжздЪЪгІадЪЙStandoutФмЙЛдкВЛЭЌЕФбЕСЗНзЖЮКЭВЛЭЌЕФЪ§ОнЕуЩЯЪЕЯжИіадЛЏЕФе§дђЛЏЧПЖШЁЃ
StandoutЕФЙЄзїдРэЃКStandoutЭЈЙ§вЛИіЖюЭтЕФЭјТчЛђВуРДМЦЫуУПИіЩёОдЊЕФБЃСєИХТЪЁЃетИіБЃСєИХТЪВЛЪЧЙЬЖЈВЛБфЕФЃЌЖјЪЧИљОнЭјТчЕБЧАЕФМЄЛюЖЏЬЌЕїећЕФЁЃОпЬхРДЫЕЃЌЖдгкУПИіЩёОдЊЃЌЦфБЃСєИХТЪЪЧЦфМЄЛюЕФКЏЪ§ЃЌетвтЮЖзХЭјТчдкбЕСЗЙ§ГЬжаздЖЏбЇЯАУПИіЩёОдЊЕФживЊадЃЌВЂОнДЫЕїећЦфБЛЖЊЦњЕФИХТЪЁЃ
StandoutЪЧЪ§бЇБэДяЪНШчЯТЃК
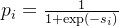
Цфжа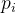 ЪЧЕк
ЪЧЕк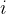 ИіЩёОдЊБЛЖЊЦњЕФИХТЪЃЌЪЧвЛИіЗТЩфКЏЪ§ЃЌПЩвдБэЪОЮЊЃК
ИіЩёОдЊБЛЖЊЦњЕФИХТЪЃЌЪЧвЛИіЗТЩфКЏЪ§ЃЌПЩвдБэЪОЮЊЃК

Цфжа КЭ
КЭ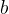 ЪЧГЌВЮЪ§ЃЌ
ЪЧГЌВЮЪ§ЃЌ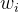 ЪЧЕкИіЩёОдЊЕФШЈжиЁЃПЩвдПДГіЃЌШЈжидНДѓЃЌЖЊЦњИХТЪдНДѓЁЃ
ЪЧЕкИіЩёОдЊЕФШЈжиЁЃПЩвдПДГіЃЌШЈжидНДѓЃЌЖЊЦњИХТЪдНДѓЁЃ
StandoutЕФPyTorchЪЕЯжЃКдкPyTorchжаЪЕЯжStandoutашвЊздЖЈвхвЛИіВуЃЌетИіВуФмЙЛИљОнЪфШыМЄЛюЖЏЬЌМЦЫуУПИіЩёОдЊЕФЖЊЦњИХТЪЁЃ
вдЯТЪЧвЛИіМђЛЏЕФЪОР§ЃЌЫЕУїШчКЮЪЕЯжетбљЕФВуЃК
import torch
import torch.nn as nn
class Standout(nn.Module):
def __init__(self, input_dim, output_dim):
super(Standout, self).__init__()
self.fc = nn.Linear(input_dim, output_dim)
# ЪЙгУвЛИіМђЕЅЕФШЋСЌНгВуРДЩњГЩБЃСєИХТЪ
self.prob_fc = nn.Linear(input_dim, output_dim)
def forward(self, x):
# МЦЫуе§ГЃЕФЧАЯђДЋВЅ
x_out = self.fc(x)
if self.training:
# МЦЫуУПИіЩёОдЊЕФБЃСєИХТЪ
probs = torch.sigmoid(self.prob_fc(x))
# ЩњГЩгыМЄЛюДѓаЁЯрЭЌЕФЖўжЕбкТы
mask = torch.bernoulli(probs).to(x.device)
# гІгУmask
x_out = x_out * mask
# зЂвтЃКдкЦРЙРФЃЪНЯТВЛгІгУStandout
return x_outдкетИіЪЕЯжжаЃЌself.prob_fc ВуЪфГіЕФЪЧУПИіЩёОдЊЕФБЃСєИХТЪЃЌЖјВЛЪЧЖЊЦњИХТЪЃЌетаЉИХТЪЭЈЙ§Sigmoid КЏЪ§НјааСЫЙщвЛЛЏЁЃНгзХЃЌЪЙгУетаЉИХТЪЩњГЩвЛИіЖўжЕбкТыЃЌИУбкТыЭЈЙ§ВЎХЌРћВЩбљЕУЕНЃЌзюКѓНЋетИібкТыгІгУЕН self.fc ВуЕФЪфГіЩЯЃЌвдЪЕЯжЩёОдЊЕФЫцЛњБЃСєЁЃ
ашвЊзЂвтЕФЪЧЃЌгЩгкStandoutЕФздЪЪгІадЃЌЫќЕФааЮЊЛсБШДЋЭГЕФDropoutЛђDropConnectИќИДдгЃЌПЩФмашвЊИќЯИжТЕФЕїВЮКЭМрПивдШЗБЃбЕСЗЮШЖЈадКЭФЃаЭадФмЁЃ
6ЁЂDropoutЕФЭиеЙ5ЃКGaussian Dropout
Gaussian Dropout ЪЧвЛжже§дђЛЏММЪѕЃЌЫќдкбЕСЗЩёОЭјТчЪБЭЈЙ§в§ШыЗўДгИпЫЙЗжВМЕФЫцЛњдыЩљРДЗРжЙЙ§ФтКЯЁЃ
ВЛЭЌгкДЋЭГ Dropout вдЙЬЖЈИХТЪНЋМЄЛюжУСуЃЌGaussian Dropout ГЫвдвЛИіЫцЛњБфСП ( m )ЃЌЦфжа ( m ) ЗўДгИпЫЙЗжВМ ( N(1, \sigma^2) )ЁЃ
PyTorch ЪОР§ЃК
import torch
import torch.nn as nn
class GaussianDropout(nn.Module):
def __init__(self, sigma=0.1):
super(GaussianDropout, self).__init__()
self.sigma = sigma
def forward(self, x):
if self.training:
# ЩњГЩЗўДгИпЫЙЗжВМ N(1, sigma^2) ЕФЫцЛњБфСП
gaussian_noise = torch.normal(1.0, self.sigma, size=x.size()).to(x.device)
# гІгУИпЫЙ dropout
return x * gaussian_noise
else:
# ВтЪдНзЖЮВЛЪЙгУ dropout
return x
# ЪЙгУЪОР§
layer = GaussianDropout(sigma=0.1)
input_tensor = torch.randn(10, 20) # МйЩшЕФЪфШы
output = layer(input_tensor)дкбЕСЗНзЖЮЃЌforward ЗНЗЈЩњГЩИпЫЙдыЩљВЂгІгУгкЪфШы xЃЌЖјдкВтЪдНзЖЮжБНгЗЕЛи xЃЌВЛгІгУдыЩљЁЃ
змНс
вдЩЯЮЊИіШЫОбщЃЌЯЃЭћФмИјДѓМввЛИіВЮПМЃЌвВЯЃЭћДѓМвЖрЖржЇГжГЬађдБжЎМвЁЃ
ЯрЙиЮФеТ

Python2.7Ацos.path.isdirжаЮФТЗОЖЗЕЛиfalseЕФНтОіЗНЗЈ
етЦЊЮФеТжївЊЮЊДѓМвЯъЯИНщЩмСЫPython2.7Ацos.path.isdirжаЮФТЗОЖЗЕЛиfalseЕФНтОіЗНЗЈЃЌОпгавЛЖЈЕФВЮПММлжЕЃЌИааЫШЄЕФаЁЛяАщУЧПЩвдВЮПМвЛЯТ2019-06-06
pytorchЖдЬнЖШНјааПЩЪгЛЏНјааЬнЖШМьВщНЬГЬ
НёЬьаЁБрОЭЮЊДѓМвЗжЯэвЛЦЊpytorchЖдЬнЖШНјааПЩЪгЛЏНјааЬнЖШМьВщНЬГЬЃЌОпгаКмКУЕФВЮПММлжЕЃЌЯЃЭћЖдДѓМвгаЫљАяжњЁЃвЛЦ№ИњЫцаЁБрЙ§РДПДПДАЩ2020-02-02
ЪЙгУPytest.main()дЫааЪБВЮЪ§ВЛЩњаЇЮЪЬтНтОі
БОЮФжївЊНщЩмСЫЪЙгУPytest.main()дЫааЪБВЮЪ§ВЛЩњаЇЮЪЬтНтОіЃЌЮФжаЭЈЙ§ЪОР§ДњТыНщЩмЕФЗЧГЃЯъЯИЃЌЖдДѓМвЕФбЇЯАЛђепЙЄзїОпгавЛЖЈЕФВЮПМбЇЯАМлжЕЃЌашвЊЕФХѓгбУЧЯТУцЫцзХаЁБрРДвЛЦ№бЇЯАбЇЯААЩ2023-02-02
Python PandasДІРэcsvЮФМўГЃгУЪОР§
PandasЪЧвЛИіЗЧГЃЧПДѓЕФЪ§ОнВйзїpythonАќ,жЇГжИїжжЪ§ОнИёЪН,АќРЈCSVЮФМў,БОЮФОЭРДНщЩмвЛЯТPython PandasДІРэcsvЮФМўГЃгУЪОР§,ИааЫШЄЕФПЩвдСЫНтвЛЯТ2023-12-12
pythonжЎpexpectЪЕЯжздЖЏНЛЛЅЕФР§зг
НёЬьаЁБрОЭЮЊДѓМвЗжЯэвЛЦЊpythonжЎpexpectЪЕЯжздЖЏНЛЛЅЕФР§згЃЌОпгаКмКУЕФВЮПММлжЕЃЌЯЃЭћЖдДѓМвгаЫљАяжњЁЃвЛЦ№ИњЫцаЁБрЙ§РДПДПДАЩ2019-07-07
НтЖСЕїгУjupyter?notebookЮФМўФкЕФКЏЪ§вЛжжМђЕЅЗНЗЈ
етЦЊЮФеТжївЊНщЩмСЫНтЖСЕїгУjupyter?notebookЮФМўФкЕФКЏЪ§вЛжжМђЕЅЗНЗЈЃЌОпгаКмКУЕФВЮПММлжЕЃЌЯЃЭћЖдДѓМвгаЫљАяжњЁЃШчгаДэЮѓЛђЮДПМТЧЭъШЋЕФЕиЗНЃЌЭћВЛСпДЭНЬ2023-01-01
pythonИпЪжжЎТЗpythonДІРэexcelЮФМў(ЗНЗЈЛузм)
гУpythonРДздЖЏЩњГЩexcelЪ§ОнЮФМўЁЃpythonДІРэexcelЮФМўжївЊЪЧЕкШ§ЗНФЃПщПтxlrdЁЂxlwtЁЂxluntilsКЭpyExceleratorЃЌГ§ДЫжЎЭтЃЌpythonДІРэexcelЛЙПЩвдгУwin32comКЭopenpyxlФЃПщ2016-01-01
pycharmШчКЮЩшжУздЖЏЩњГЩзїепаХЯЂ
етЦЊЮФеТжївЊНщЩмСЫpycharmШчКЮЩшжУздЖЏЩњГЩзїепаХЯЂЃЌОпгаКмКУЕФВЮПММлжЕЃЌЯЃЭћЖдДѓМвгаЫљАяжњЁЃШчгаДэЮѓЛђЮДПМТЧЭъШЋЕФЕиЗНЃЌЭћВЛСпДЭНЬ2022-02-02
PythonАВзАВЂВйзїredisЪЕЯжСїГЬЯъНт
етЦЊЮФеТжївЊНщЩмСЫPythonАВзАВЂВйзїredisЪЕЯжСїГЬЯъНт,ЮФжаЭЈЙ§ЪОР§ДњТыНщЩмЕФЗЧГЃЯъЯИЃЌЖдДѓМвЕФбЇЯАЛђепЙЄзїОпгавЛЖЈЕФВЮПМбЇЯАМлжЕ,ашвЊЕФХѓгбПЩвдВЮПМЯТ2020-10-10
НтОіpython replaceКЏЪ§ЬцЛЛЮоаЇЮЪЬт
дкБОЦЊЮФеТРяаЁБрИјДѓМвећРэЕФЪЧвЛЦЊЙигкpython replaceКЏЪ§ЬцЛЛЮоаЇЮЪЬтЕФНтОіЗНЗЈЃЌашвЊЕФХѓгбУЧПЩвдВЮПМЯТЁЃ2020-01-01


зюаТЦРТл