



SQL数据去重的七种方法小结
(福利推荐:你还在原价购买阿里云服务器?现在阿里云0.8折限时抢购活动来啦!4核8G企业云服务器仅2998元/3年,立即抢购>>>:9i0i.cn/aliyun)
在平时工作中,使用SQL语句进行数据去重的场景非常多。
今天主要分享几种数据去重的SQL写法。
假如有一张student表,结构如下:
create table student(
id int,
name varchar(50),
age int,
address varchar(100)
);表中的数据如下:

方法一:使用DISTINCT关键字进行去重
在使用DISTINCT关键字去重时,后面跟上去重的字段即可。
比如,取出student表中,不重复的address有哪些,可以使用如下SQL语句:
select distinct address from student;
返回结果如下:

这种方法,最大的优点是使用起来比较简单。
但也有一个比较大的缺点,就是最终返回的结果集中的字段最多只包含去重的字段。也就是说,在上面的SQL语句中,使用address字段进行去重,最终的结果,也最多只能返回address一个字段。
如果想以address字段去重,并且同时返回其他字段,DISTINCT是做不到的。
方法二:使用GROUP BY关键字进行去重
与DISTINCT关键字一样,GROUP BY关键字,也是标准SQL支持的常用的去重方法。它可以在去重的同时,同步返回其他字段的信息。
还是以对address字段进行去重为例,其他字段可以使用聚合函数根据需要进行获取:
select min(id),
max(name),
max(age),
address
from student
group by address;返回结果如下:

在上面的语句中,不仅对address字段进行了去重,也同时返回了id、name、age字段的信息。
在这一点上,比DISTINCT要好用很多。
不过,仔细一看,好像总是觉得哪里不对劲。
id=1的学生,应该叫周俊廷,而在上面的返回结果中却是杨萧语,返回的age字段,也有同样的问题。
也就是说,在返回的结果中,同一行的id、name、age,可能并不是同一个学生的,这就导致看起来数据有些混乱。
如果对数据的一致性有要求,可以使用下面的第三种方法。
方法三:使用窗口函数进行去重
窗口函数有好几种,使用起来大同小异,这里只介绍ROW_NUMBER() over(partition by ... order by ...)。
select
id,name,age,address
from (
select id,name,age,address,
row_number() over(
partition by address
order by id asc
) as rn
from student
)a
where a.rn = 1;ROW_NUMBER()窗口函数的原理是,先对数据按照partition by的字段进行分组,然后以order by的字段在各个分组内进行排序,序号从1开始递增。
上面的SQL返回的结果为:

这个返回结果,就完美多了。
但是,需要注意的是,有些数据库是不支持窗口函数的。像低版本的MySQL数据库中就无法使用。
方法四:使用IN去重
这种方法的关键在于,找到一组不重复的数据的特征,然后以这个特征来取数据。
比如:按address来去重,如果数据有重复,取id最大的那条。
select *
from student
where id in (
select max(id)
from student
group by address
);返回结果如下:

当然,也可以取id最小的那条,将上面语句中的max改成min就可以了。
这种方法适合表里有一个数据不重复的字段(如上面SQL中的id字段)的情况。
如果表中不存在这样一个字段,这种方法就不再适用了。但有些数据库,天生自带了类似的字段可以使用。
比如,在ORACLE数据库中,可以使用ROWID替代上面SQL中的id字段。当然仅限于ORACLE数据库:
select *
from student
where rowid in (
select max(rowid)
from student
group by address
);方法五:使用NOT EXISTS去重
与方法四的思路类似,使用NOT EXISTS也可以实现同样的效果。
select *
from student a
where not exists(
select 1
from student b
where a.address = b.address
and a.id > b.id
);返回结果如下:
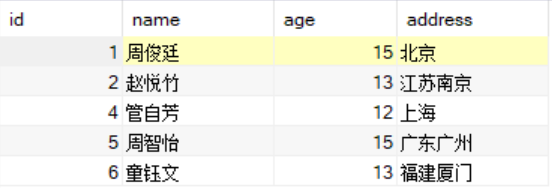
方法六:使用ALL关键字
在MySQL数据库中,有一个特殊的操作符ALL,这是一个集合操作符,表示子数据集中的所有数据都满足某一个条件。
select *
from student a
where a.id <= ALL(
select b.id
from student b
where a.address = b.address
);返回结果如下:

在上面的SQL中,ALL操作符的意思是说,a.id字段要<=ALL操作符括号里查询出来的所有值。
这种方法的核心思路与方法四是类似的。
方法七:使用INNER JOIN + GROUP BY关键字
这种方法的核心思路,也与方法四是类似的。
select
a.*
from student a
inner join student b
on a.address = b.address
and a.id >= b.id
group by a.id,a.name,a.age,a.address
having count(*)=1;返回结果如下:

上面介绍了7种数据去重的方法,你知道几种?
到此这篇关于SQL数据去重的七种方法小结的文章就介绍到这了,更多相关SQL数据去重内容请搜索程序员之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持程序员之家!
相关文章
 2008-01-01
2008-01-01 触发器是数据库应用中的重用工具,它的应用很广泛。这几天写一个化学数据统计方面的软件,需要根据采样,自动计算方差,在这里,我使用了触发器。2009-09-09
触发器是数据库应用中的重用工具,它的应用很广泛。这几天写一个化学数据统计方面的软件,需要根据采样,自动计算方差,在这里,我使用了触发器。2009-09-09
sqlserver 数据库压缩与数据库日志(ldf)压缩方法分享
数据库在使用中,冗余的数据不断的增加(数据删除也不会减小),导致数据库不断的增大!所以该给你的数据库减减肥了2011-12-12 SQL Server 的 SQL 语句导入导出大全...2006-12-12
SQL Server 的 SQL 语句导入导出大全...2006-12-12 sqlserver 锁表语句分享,需要的朋友可以参考下2012-01-01
sqlserver 锁表语句分享,需要的朋友可以参考下2012-01-01 tempdb:是连接到 SQL Server 实例的所有用户都可用的全局资源,它保存所有临时表,临时工作表,临时存储过程,临时存储大的类型,中间结果集,表变量和游标等。另外,它还用来满足所有其他临时存储要求.2016-01-01
tempdb:是连接到 SQL Server 实例的所有用户都可用的全局资源,它保存所有临时表,临时工作表,临时存储过程,临时存储大的类型,中间结果集,表变量和游标等。另外,它还用来满足所有其他临时存储要求.2016-01-01 在使用SQL Server数据库的过程中我们经常会遇到需要将行数据和列数据相互转换显示的问题,本文就来介绍一下,具有一定的参考价值,感兴趣的可以了解一下2023-09-09
在使用SQL Server数据库的过程中我们经常会遇到需要将行数据和列数据相互转换显示的问题,本文就来介绍一下,具有一定的参考价值,感兴趣的可以了解一下2023-09-09 这是一个人事系统中的示例,要求记录一下员工的缺勤情况2011-10-10
这是一个人事系统中的示例,要求记录一下员工的缺勤情况2011-10-10 对于数据库运维人员来说创建session或者查询时产生问题是常规情况,下面介绍一种很有效且不借助第三方工具的方式来解决类似问题,需要的朋友可以参考下2016-10-10
对于数据库运维人员来说创建session或者查询时产生问题是常规情况,下面介绍一种很有效且不借助第三方工具的方式来解决类似问题,需要的朋友可以参考下2016-10-10
Linux环境安装SQL?Server数据库以及使用方法详解
很多朋友在安装SQL Server的过程中会碰到一些小状况,下面这篇文章主要给大家介绍了关于Linux环境安装SQL?Server数据库以及使用方法的相关资料,需要的朋友可以参考下2024-02-02


最新评论