



Dbeaver做数据迁移的详细过程记录
(福利推荐:你还在原价购买阿里云服务器?现在阿里云0.8折限时抢购活动来啦!4核8G企业云服务器仅2998元/3年,立即抢购>>>:9i0i.cn/aliyun)
1、选择源头数据库的表、鼠标右击、选择导出数据
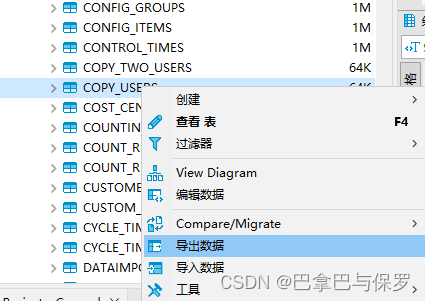
2、在数据转化弹框中,双击 ‘数据库,数据表’ 那一栏
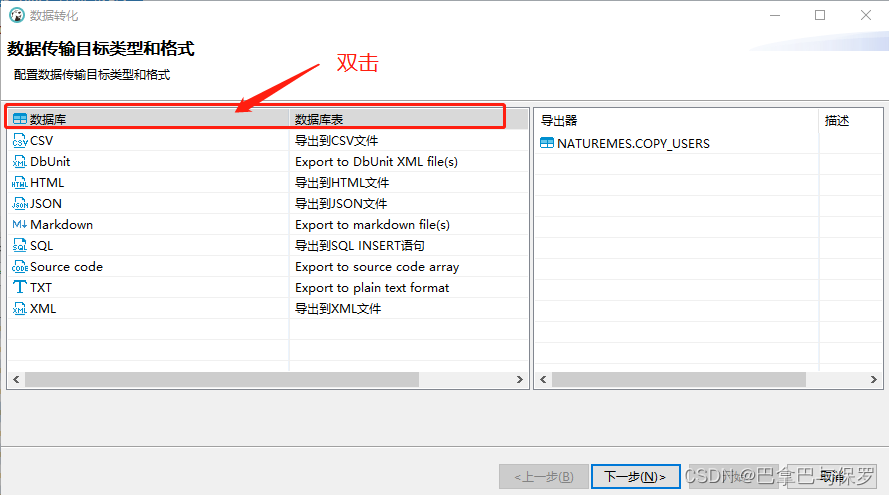
3、选择目标数据库,调整字段类型映射关系
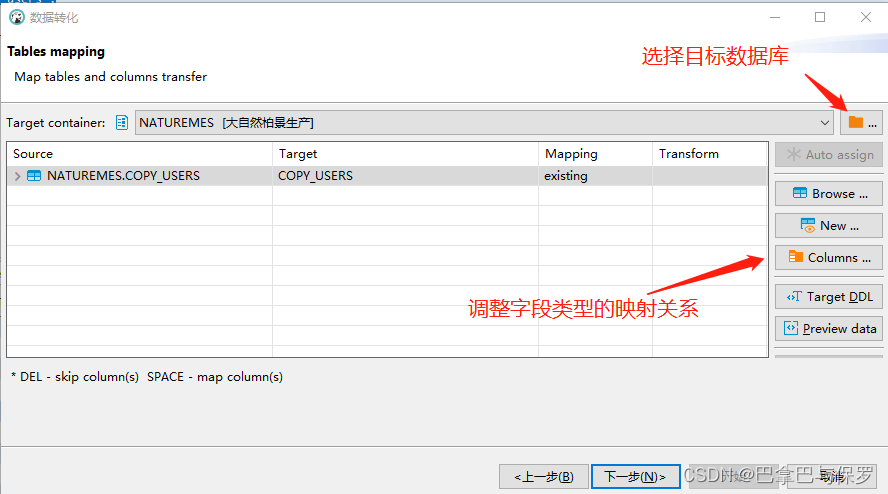
4、调整字段的映射关系
目前遇到的字段类型,只有 int,bigint 转 number 类型
再就是VARCHAR2 长度不够的,加长度,超过4000的就改为clob类型
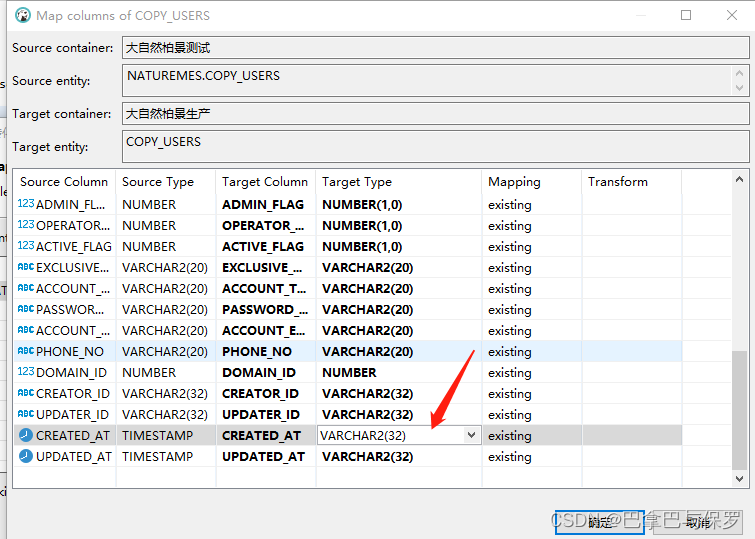
5、勾选‘打开新连接’,‘选择行计数’
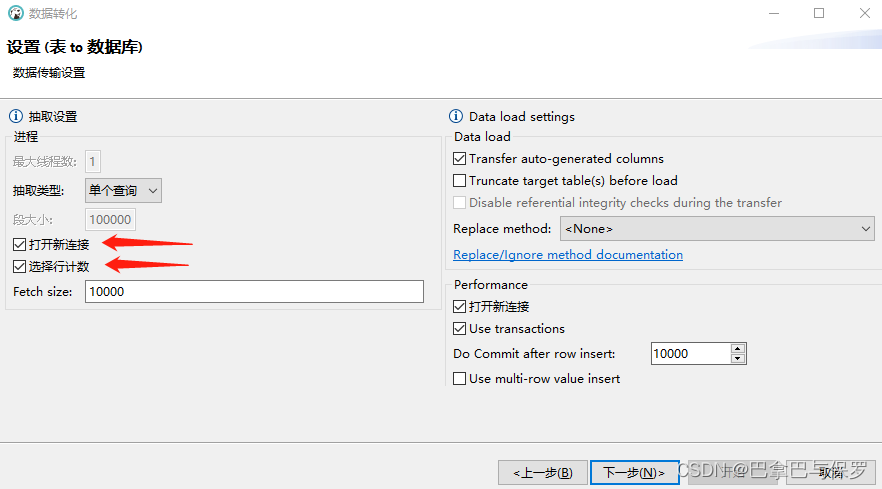
6、点击开始
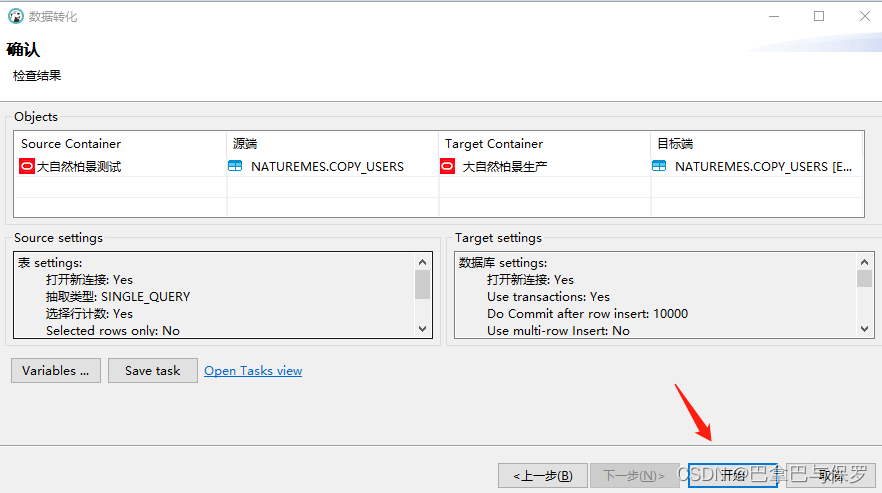
7、注意事项
A、如果是Oracle转Oracle,同类型的数据库迁移,就不用管字段类型的映射关系了
B、如果字段的映射不对就会报错,或者表创建了,但数据没有进去
C、遇到的字段类型,只有 int,bigint 转 number 类型
D、有些字段迁移后会变成小写,需要后面手动调整
可以用SQL查询出所有的小写字段
select column_name,table_name from user_tab_columns where regexp_like(column_name,'[a-z]');
E、VARCHAR2(200) 类型可能存在 实际长度大于限制长度的问题,会报错出来
超过4000的长度,可以改为 clob 类型
F、VARCHAR2 类型如果没有限制长度,会报错:“缺少括号”,加就可以了 VARCHAR2(200)
G、数据迁移后,对比两个数据库表的数量,可以使用SQL查询数量
H、表迁移后,发现索引都没有迁移
导致登录的时候报错:
java.lang.IllegalArgumentException: obj is null
处理方式:迁移索引后,问题就自动好了
8、处理方式总结
A、导出时,可以批量的处理,比如一次处理10个表,遇到报错就停止执行,这样后面再处理报错的表就可以了,其他表会都迁移了。报错的表需要删除了,从新迁移。删除表后,需要刷新数据库。
B、批量迁移索引
使用SQL 查询出SQL server 所有创建索引的语句。下面是SQL
WITH indexInfo as (
SELECT SCHEMA_NAME(t.schema_id) [schema_name],t.name as [table_name],t1.name as [index_name]
,t1.type,t1.type_desc,t1.is_unique,t1.is_primary_key,t1.is_unique_constraint,t1.has_filter,t1.filter_definition
,STUFF((SELECT ','+t4.name FROM sys.sysindexkeys t2
inner join sys.index_columns t3 ON t2.id=t3.object_id and t2.indid=t3.index_id and t2.colid=t3.column_id
inner join sys.syscolumns t4 ON t2.id=t4.id and t2.colid=t4.colid
WHERE t2.id=t1.object_id and t1.index_id=t2.indid and t2.keyno <> 0 ORDER BY t3.key_ordinal FOR XML PATH('')),1,1,'') AS index_cols
,STUFF((SELECT ','+t4.name FROM sys.sysindexkeys t2
inner join sys.index_columns t3 ON t2.id=t3.object_id and t2.indid=t3.index_id and t2.colid=t3.column_id
inner join sys.syscolumns t4 ON t2.id=t4.id and t2.colid=t4.colid
WHERE t2.id=t1.object_id and t1.index_id=t2.indid and t2.keyno = 0 ORDER BY t3.key_ordinal FOR XML PATH('')),1,1,'') AS include_cols
FROM sys.tables as t
inner join sys.indexes as t1 on (t1.index_id > 0 and t1.is_hypothetical = 0) and (t1.object_id=t.object_id)
WHERE t1.type in(1,2)
), indexInfo2 AS (
SELECT * ,(CASE
WHEN is_primary_key = 1
THEN 'alter table '+[schema_name]+'.'+[table_name]+' add constraint '+[index_name]+' primary key '+(CASE WHEN [type]=1 THEN 'clustered' ELSE 'nonclustered' END)+'('+index_cols+');'
WHEN is_unique = 1 AND is_unique_constraint = 1
THEN 'alter table '+[schema_name]+'.'+[table_name]+' add constraint '+[index_name]+' unique '+(CASE WHEN [type]=1 THEN 'clustered' ELSE 'nonclustered' END)+'('+index_cols+');'
WHEN is_unique = 1 AND (is_primary_key = 0 OR is_unique_constraint = 0)
THEN 'create unique '+(CASE WHEN [type]=1 THEN 'clustered' ELSE 'nonclustered' END)+' index '+[index_name]+' on '+[schema_name]+'.'+[table_name]+'('+index_cols+');'
ELSE 'create '+(CASE WHEN [type]=1 THEN 'clustered' ELSE 'nonclustered' END)+' index '+[index_name]+' on '+[schema_name]+'.'+[table_name]+'('+index_cols+') ;'
END) script
FROM indexInfo
) SELECT [schema_name],[table_name],[index_name],script
+(CASE WHEN include_cols IS NOT NULL THEN ' include('+include_cols+')' ELSE '' END)
+(CASE WHEN has_filter = 1THEN ' where '+filter_definition ELSE '' END)
FROM indexInfo2
ORDER BY [schema_name],[table_name],[type],[index_name],is_primary_key DESC,is_unique_constraint DESC,is_unique DESCC、批量处理语句后(两种数库的DDL语句有所差异),可以批量执行。
可以全部一起执行,或者一次执行50条语句,遇到报错就停止,报错前的语句都执行了,就可以删除了。处理报错后,再执行报错后面的语句。
有些不好处理的报错,可以先不管,后面在手动对表建索引就可以了
批量执行DDL语句的方式
新开个窗口放DDL语句,SQL编辑器 --> 执行SQL脚本
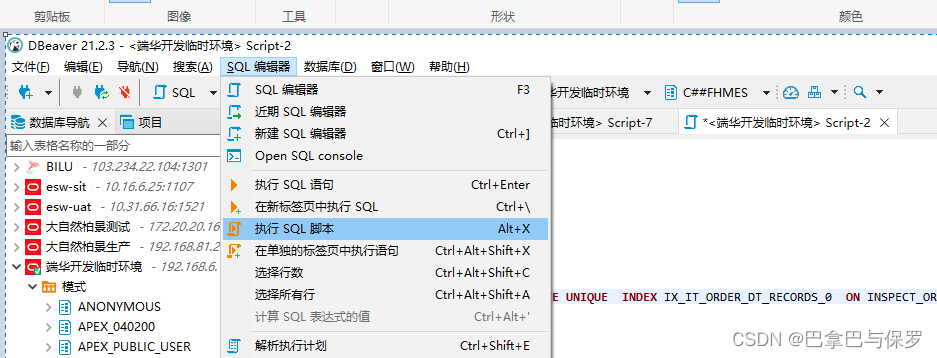
注意事项:
SQL SERVE 迁移到 ORACLE 后,在 ‘数据库表管理’ 页面做表创建的时候,DDL语句会报错,因为字段都是小写,且都加了引号,导致Oracle不能识别。需要删除 D:\03_workspace\01_fenghua\02_server\fenghua-tmp-server\src\main\java\xyz\elidom\dbist\ddl\impl\DdlJdbc.java 文件,删除后重启后端,就可以了,
后面生成的DDL语句,字段就没引号了,Oracle就可以正常创建表了。
总结
到此这篇关于Dbeaver做数据迁移的文章就介绍到这了,更多相关Dbeaver数据迁移内容请搜索程序员之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持程序员之家!
相关文章
 Hive内部表:默认创建的表是内部表,Hive外部表:外部表的数据不是Hive拥有或者管理的,只管理元数据的声明周期,本文详细介绍了hive内部表和外部表的区别,感兴趣的小伙伴可以参考阅读2023-04-04
Hive内部表:默认创建的表是内部表,Hive外部表:外部表的数据不是Hive拥有或者管理的,只管理元数据的声明周期,本文详细介绍了hive内部表和外部表的区别,感兴趣的小伙伴可以参考阅读2023-04-04
在SQL SERVER中查询数据库中第几条至第几条之间的数据SQL语句写法
这篇文章主要介绍了在SQL SERVER中查询数据库中第几条至第几条之间的数据SQL语句写法,需要的朋友可以参考下2015-11-11 这篇文章主要介绍了关于hive中SQL的执行原理解析,Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能,需要的朋友可以参考下2023-07-07
这篇文章主要介绍了关于hive中SQL的执行原理解析,Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能,需要的朋友可以参考下2023-07-07 这篇文章主要介绍了一款免费开源的通用数据库工具DBeaver,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-10-10
这篇文章主要介绍了一款免费开源的通用数据库工具DBeaver,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-10-10 不管是用C/C++/Java等代码编写的程序,还是SQL编写的数据库脚本,都存在一个持续优化的过程。也就是说,代码优化对于程序员来说,是一个永恒的话题。下面这篇文章主要给大家总结介绍了90%程序员在面试的时候会遇到的索引优化问题,需要的朋友可以参考下。2017-11-11
不管是用C/C++/Java等代码编写的程序,还是SQL编写的数据库脚本,都存在一个持续优化的过程。也就是说,代码优化对于程序员来说,是一个永恒的话题。下面这篇文章主要给大家总结介绍了90%程序员在面试的时候会遇到的索引优化问题,需要的朋友可以参考下。2017-11-11 这篇文章主要为大家介绍了关于SQL查询语法的知识梳理总结,文中附含详细的查询语法示例,有需要的朋友可以借鉴参考下,希望能够有所帮助2021-10-10
这篇文章主要为大家介绍了关于SQL查询语法的知识梳理总结,文中附含详细的查询语法示例,有需要的朋友可以借鉴参考下,希望能够有所帮助2021-10-10 这篇文章主要介绍了SQL中IS NOT NULL与!=NULL的区别,本文详细诉说了它们的区别,以及推荐使用方法,需要的朋友可以参考下2015-06-06
这篇文章主要介绍了SQL中IS NOT NULL与!=NULL的区别,本文详细诉说了它们的区别,以及推荐使用方法,需要的朋友可以参考下2015-06-06 本文主要对sql server 公共表达式的简单应用进行介绍,具有一定的参考价值,有需要的可以看下2016-12-12
本文主要对sql server 公共表达式的简单应用进行介绍,具有一定的参考价值,有需要的可以看下2016-12-12![SQL服务器面临的危险和补救.读[十种方法]后感.](http://9i0i.com/pic.php?p=http://img.jbzj.com/images/xgimg/bcimg8.png) SQL服务器面临的危险. 危险:没有防火墙保护,暴露在公网中. 后果:SQL蠕虫感染和黑客进行拒绝服务攻击、缓存溢出、SQL盲注和其它攻击. 补救:安装一款防火墙,即使经费有限,网上也有大把的免费产品.2008-05-05
SQL服务器面临的危险. 危险:没有防火墙保护,暴露在公网中. 后果:SQL蠕虫感染和黑客进行拒绝服务攻击、缓存溢出、SQL盲注和其它攻击. 补救:安装一款防火墙,即使经费有限,网上也有大把的免费产品.2008-05-05 需要用到mssql数据同步的朋友可以参考本文和上一篇文章2008-09-09
需要用到mssql数据同步的朋友可以参考本文和上一篇文章2008-09-09


最新评论