



如何使用正则匹配最后一个字符串详解
(福利推荐:你还在原价购买阿里云服务器?现在阿里云0.8折限时抢购活动来啦!4核8G企业云服务器仅2998元/3年,立即抢购>>>:9i0i.cn/aliyun)
前几天遇到一个需求,输入的是
<user>
<user>
<name>a</name>
</user>
<user>
<name>a</name>
</user>
</user>
<password>123</password>
要求拿到
<user>
<user>
<name>a</name>
</user>
<user>
<name>a</name>
</user>
</user>
也就是去掉最后一个</user>后面的字符串。
方法有很多,我首先想到的是用正则匹配去掉</user>后面的字符串。
最后写出来的表达式是
(?<=</user>)(?![\w\W]*</user>)[\w\W]+。
首先用(?<=</user>)匹配所有前面是</user>的位置,如图,总共有三个位置。
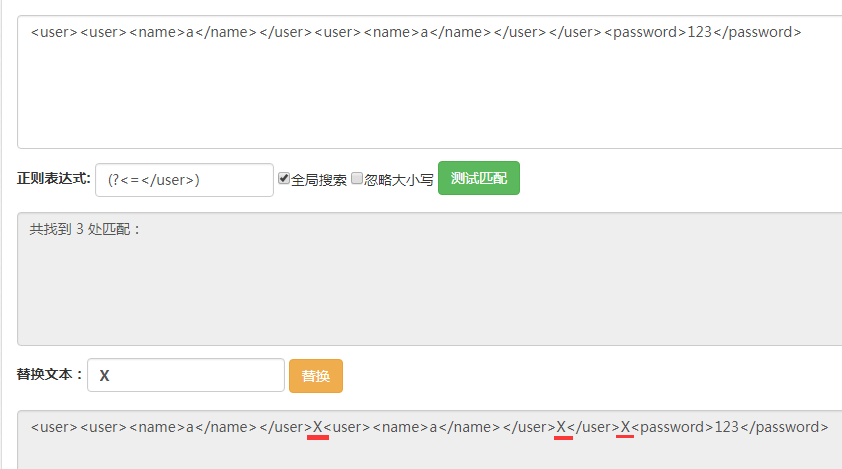
这里我们正则表达式(?<=</user>)的意思就是匹配的位置之前的字符串是</user>,也就是我们匹配到的位置在</user>之后。
这里用到了正则表达式语法中的断言,有的书上也称该语法为预查或者环视,都是一样的用法。有如下语法:
(?=pattern) 零宽正向先行断言 (?!pattern) 零宽负向先行断言 (?<=pattern) 零宽正向后行断言 (?<!pattern) 零宽负向后行断言
这里用到的是(?<=pattern),零宽表示它匹配的是在字符串中的位置,如同^匹配字符串串首,$匹配字符串串尾。正向代表它必须满足pattern。后行代表它匹配的位置在pattern之后。
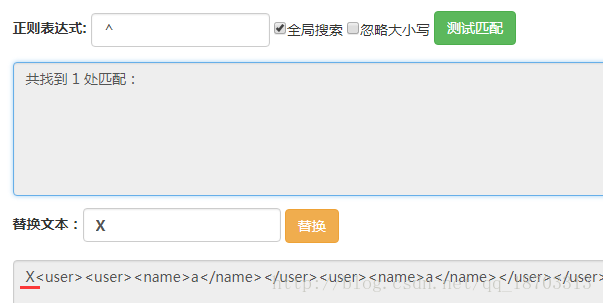
其次,再这三个位置上进行筛选,能够看出这三个位置的区别是后面是否有</user>,如果没有的话那么它就是最后一个</user>后面的位置。在之前的表达式后面添上(?![\w\W]*?</user>)此时表达式变为(?<=</user>)(?![\w\W]*?</user>)。

能够看到得到了最后一个匹配结果。
这里的正则表达式(?!pattern) 是零宽负向先行断言,也就是它会往后匹配pattern,匹配到的位置在pattern之前,并且匹配到的字符串必须不满足pattern。
(?![\w\W]*?</user>)的意思是在匹配到的位置后面必须不是[\w\W]*?</user>,\w匹配的是[a-zA-Z0-9_]即匹配字母数字和下划线,而\W匹配的是[^a-zA-Z0-9_]即不是字母数字也不是下划线的字符,同时匹配这两个就相当于匹配任意字符。[\w\W]后面的*代表匹配0-任意多次,后面的?代表懒惰模式,即只要满足条件就立即返回。
最后,在之前的正则表达式后面加上[\w\W]+贪婪匹配即尽可能多的匹配该位置后面的字符串。最终的正则表达式是(?<=</user>)(?![\w\W]*?</user>)[\w\W]*
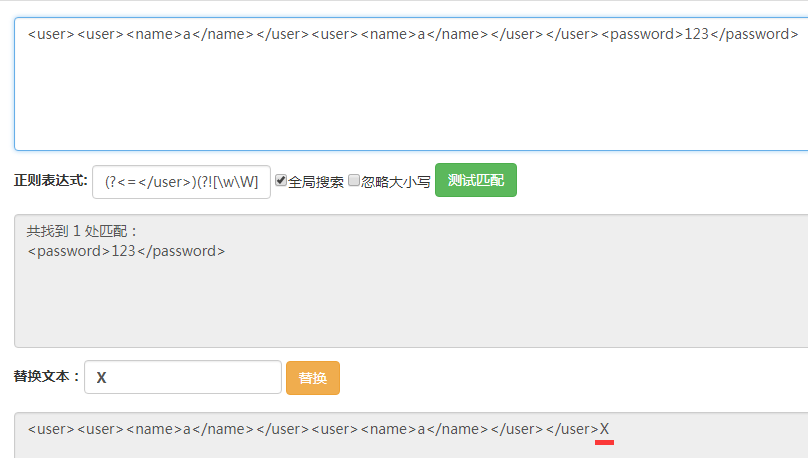
最后的最后用四张图简单地描述四种断言的不同之处。
这里输入的字符串都是123456。
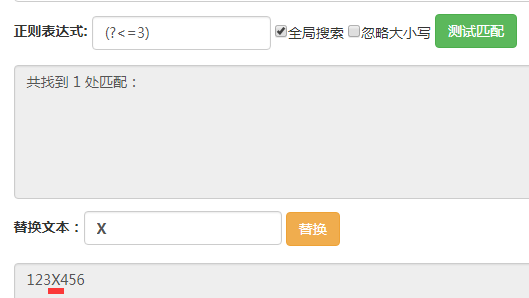
(?=3),它匹配的位置是后面的字符为3的位置。
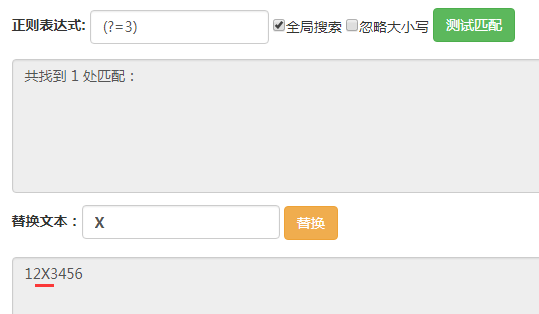
(?<=3),它匹配的位置是前面的字符为3的位置。
(?!3)匹配的位置是后面的字符不为3的位置,可以看到箭头所指的地方没有被匹配到,其他位置都被匹配到了。
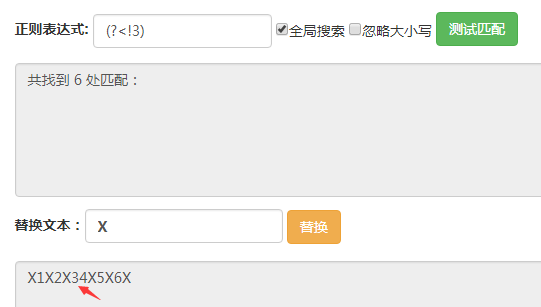
(?<!3)匹配的位置是前面的字符不为3的位置,可以看到箭头所指的地方没有被匹配到,其他位置都被匹配到了。
总结
到此这篇关于如何使用正则匹配最后一个字符串详解的文章就介绍到这了,更多相关正则匹配最后一个字符串内容请搜索程序员之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持程序员之家!
相关文章
 这是一篇翻译文章。我学过很多次正则表达式,总是学了忘,忘了学,一到用的时候还是只能靠搜索引擎2020-05-05
这是一篇翻译文章。我学过很多次正则表达式,总是学了忘,忘了学,一到用的时候还是只能靠搜索引擎2020-05-05 JScript中正则表达函数的说明与应用...2007-04-04
JScript中正则表达函数的说明与应用...2007-04-04 正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子,通俗的讲就是按照某种规则去匹配符合条件的字符串2023-12-12
正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子,通俗的讲就是按照某种规则去匹配符合条件的字符串2023-12-12 本文是一系列关于Python正则表达式文章的其中一部分。在这个系列的第一篇文章中,我们将重点讨论如何使用Python中的正则表达式并突出Python中一些独有的特性2014-08-08
本文是一系列关于Python正则表达式文章的其中一部分。在这个系列的第一篇文章中,我们将重点讨论如何使用Python中的正则表达式并突出Python中一些独有的特性2014-08-08 这篇文章主要给大家介绍了关于正则表达式的神奇世界之表达、匹配和提取的相关资料,正则表达式是由一些特定的字符组成,代表一个规则,可以用来检验数据格式是否合法,也可以在一段文本中查找满足要求的内容,需要的朋友可以参考下2024-02-02
这篇文章主要给大家介绍了关于正则表达式的神奇世界之表达、匹配和提取的相关资料,正则表达式是由一些特定的字符组成,代表一个规则,可以用来检验数据格式是否合法,也可以在一段文本中查找满足要求的内容,需要的朋友可以参考下2024-02-02
AS3 js正则表达式 反向引用(backreference)
这篇文章主要介绍了AS3 js正则表达式 反向引用(backreference) 的相关资料,需要的朋友可以参考下2016-03-03 临时记录:一个正则...2006-12-12
临时记录:一个正则...2006-12-12 这篇文章主要介绍了正则表达式匹配各种特殊字符的相关知识,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2019-08-08
这篇文章主要介绍了正则表达式匹配各种特殊字符的相关知识,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2019-08-08 JavaScript经常会验证中文本文将提供使用正则表达式实现,接下来介绍两个实例,感兴趣的你可不要错过了哈,希望本例知识点可以帮助到你2013-02-02
JavaScript经常会验证中文本文将提供使用正则表达式实现,接下来介绍两个实例,感兴趣的你可不要错过了哈,希望本例知识点可以帮助到你2013-02-02
JavaScript正则方法replace实现搜索关键字高亮显示
这里介绍的是JavaScript的正则表达式的replace方法 ,和实现搜索关键字高亮的功能.先介绍一下正则表达式的replace方法,具体内容详情大家参考下本文2017-09-09


最新评论